实现一个有序集合有多种方式:数组、链表、平衡树等,每种方式都有其优缺点:
- 数组查询效率高,但需要申请连续的内存空间,且插入删除需要移动大量元素;
- 链表不需要申请连续空间,插入删除效率高,但查询效率低;
- 平衡树或红黑树效率较高但实现复杂,不容易维护。
Redis 中的有序集合 zset 支持快速查找,并支持范围查询,底层使用跳跃表实现,跳跃表对比平衡树或红黑树,查询效率相当,但原理及实现方式简单得多,便于维护。
跳跃表的基本原理
跳跃表基于有序链表,通过空间换时间的方式,支持快速查找,其基本原理是在有序链表的基础上建立分层索引,每一层索引也是有序链表。
一个普通的有序链表实例:

在有序数组中,我们可以通过下标访问的方式使用二分查找提高查询效率,对于有序链表来说,我们如何建立索引,来达到二分查找的效果呢?一个简单的方式是:从完整链表中,选取部分节点构建一个新的链表作为索引,索引节点拥有两个方向的指针,一个指向同层索引的下一个节点,一个指向低一层的原始节点,按照这个规则建立几层索引后,最上层索引节点数远小于原始节点数:
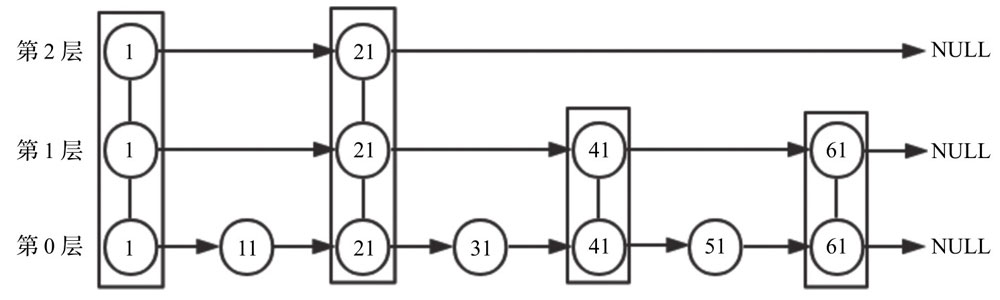
这样一来,我们在查询某个节点的时候,先从一层索引开始查找,查找到合适的位置,然后下降到低一层索引,以此类推,这就是跳跃表的基本原理。
Redis 中的跳跃表
基本结构
typedef struct zskiplistNode {
sds ele;
double score;
struct zskiplistNode *backward;
struct zskiplistLevel {
struct zskiplistNode *forward; /* 指向同层索引的下个节点 */
unsigned long span; /* 跳过的节点个数 */
} level[];
} zskiplistNode;
typedef struct zskiplist {
struct zskiplistNode *header, *tail;
unsigned long length; /* 原始节点总数 */
int level; /* 跳跃表高度,即节点最大层数 */
} zskiplist;
ele 用于存储字符串类型数据,score 存储排序的分值。由于高一层索引中的节点必然存在于低一层索引中,所以 zskiplistNode 使用 level 数组来聚合垂直方向的索引节点,同时增加 backward 指针指向前一个节点,用于支持反向遍历,一个典型的 Redis 跳跃表结构如下:
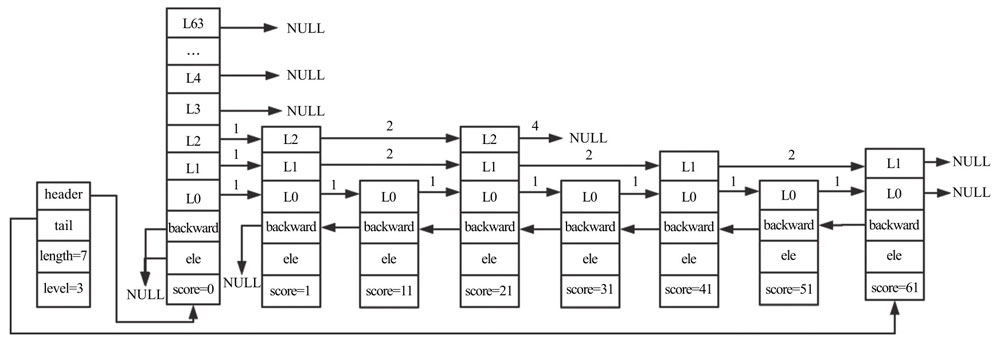
索引的维护
很显然,节点的插入和删除需要重新维护索引,如果不维护索引,在极端情况下,两个节点间插入的新节点越来越多,最终跳跃表会退化为有序单链表。
根据 Redis 跳跃表节点的定义可知,level 数组的大小决定了每个节点在各层索引中是否存在,新加入节点的高度由 zslRandomLevel 给定:
#define ZSKIPLIST_MAXLEVEL 32
#define ZSKIPLIST_P 0.25
int zslRandomLevel(void) {
int level = 1;
while ((random()&0xFFFF) < (ZSKIPLIST_P * 0xFFFF))
level += 1;
return (level<ZSKIPLIST_MAXLEVEL) ? level : ZSKIPLIST_MAXLEVEL;
}
level 初始值为 1,在循环中每次生成一个随机值,并取低 16 位和 0.25 倍的 0xFFFF 相比较,来决定高度是否加 1,节点层高最大不超过 32。层数为 i 时,概率为 (1-p)*p^(i-1),通过等比数列计算公式可知,层高在默认参数下的期望值为 1/(1-p) = 1.33。
为新节点分配空间并初始化后,需要修改各层索引的指针并更新跳跃表的 level 信息。
参考资料:
- Redis 5 设计与源码分析 —— 陈雷